Disaster Recovery (DR) – это набор инструментов и методов для восстановления IT-инфраструктуры после аварии. Причины катастроф и сбоев могут быть разными: от неправильно установленного ПО, до серьезного природного или техногенного катаклизма. Устойчивость системы и максимально быстрое восстановление после критического ущерба – важнейшие элементы безопасности почти любого современного бизнеса, использующего информационные технологии.
Комплекс мер по восстановления системы обычно оформляют как план, в соответствии с которым будет действовать обслуживающий персонал после возникновения инцидента. Disaster Recovery Plan (DRP) в первую очередь требуется организациям с развитой IT-инфраструктурой. Небольшому бизнесу иногда достаточно грамотно реализовать схему резервного копирования, чтобы обеспечить приемлемый уровень безопасности.
 Специально для вас мы изучили расценки на услуги Disaster Recovery от 20 крупных европейских провайдеров. Если вы хотите получить эту информацию, оценить или скорректировать собственный DRP план, забронируйте бесплатную консультацию со специалистом по облачным сервисам. Мы поможем посчитать смету, затраты на реализацию, расскажем про лизинг оборудования для аварийного восстановления. Забронировать разговор можно здесь.
Специально для вас мы изучили расценки на услуги Disaster Recovery от 20 крупных европейских провайдеров. Если вы хотите получить эту информацию, оценить или скорректировать собственный DRP план, забронируйте бесплатную консультацию со специалистом по облачным сервисам. Мы поможем посчитать смету, затраты на реализацию, расскажем про лизинг оборудования для аварийного восстановления. Забронировать разговор можно здесь.Для чего нужен Disaster Recovery Plan
Главная задача мер по аварийному восстановлению – исключение негативных последствий для сервисов или минимизация ущерба в случае аварии. Полноценное планирование ( Disaster Recovery Planning) преследует сразу несколько целей:
- Заранее создать альтернативные и дублирующие системы эксплуатации.
- Обучить и подготовить персонал к возможным авариям.
- Свести к минимуму ущерб и предотвратить возможное разрушение IT-инфраструктуры.
- Ограничить время отказа системы до приемлемых значений или вовсе исключить остановку работы сервисов.
- Минимизировать экономические последствия в случае инцидента.
- Обеспечить быстрое восстановление сервиса.
Количество используемых инструментов и предпринимаемых мер прямо зависит от масштаба IT-инфраструктуры.
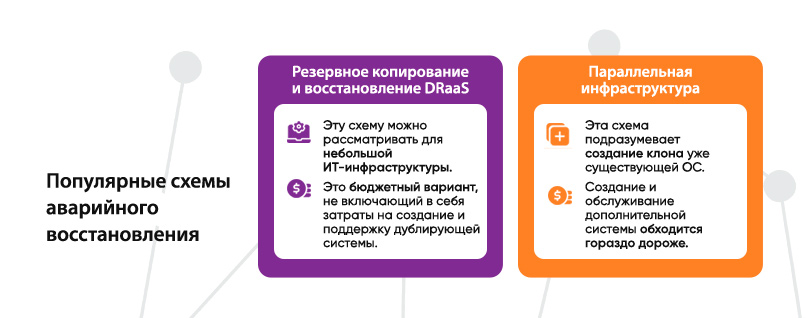
Популярные схемы Disaster Recovery
Перечень мер по аварийному восстановлению определяют, исходя из вероятных рисков и целесообразности затрат на необходимый уровень безопасности. Например, маленькой компании эксплуатирующей один сервер и ограниченный набор сетевого оборудования, скорее всего, просто нет необходимости разрабатывать и внедрять полноценное DRP планирование (drp planning). В этом случае достаточно обычного создания бэкапов в облаке и облачных средств восстановления. А вот активно растущему бизнесу и крупным компаниям требуются комплексные решения по аварийному восстановлению.
- DRaaS Backup & Restore – схема, которая может рассматриваться в контексте мер Disaster Recovery для небольшой IT-инфраструктуры. Это бюджетный вариант, который не предусматривает затрат на создание и поддержание дублирующей системы. Платить нужно лишь за объем в облаке и время работы виртуальных машин на момент аварии. Почти все крупные европейские провайдеры могут предоставить готовые решения по созданию бэкапов и восстановлений из облака.
- Parallel infrastructure – предполагает создание клона уже работающей системы. В случае аварии на основной структуре автоматически включается параллельная. Такой метод позволяет значительно сократить издержки: время запуска дублирующей инфраструктуры может составлять от нескольких десятков минут до суток. В то же время, создание и содержание дополнительной системы обходится намного дороже, поэтому используется компаниями, для которых простой в десятки минут является критичным.
В этой статье подробнее остановимся на особенностях внедрения параллельной инфраструктуры, поскольку именно для этой схемы план аварийного восстановления (DRP) может являться важным элементом безопасности.
При создании параллельной инфраструктуры совсем не обязательно создавать полноценный клон основной системы. Часто для аварийного восстановления резервируют менее производительное оборудование. Более того, на резервные сервера выносят лишь данные и сервисы, которые являются критичными для бизнеса: DRP, MES, CRM и т.д. Например, если основная IT-инфраструктура представлена десятью серверами, то параллельную можно запустить на двух резервных, их задача – обеспечить приемлемый уровень доступа к самым важным данным и сервисам лишь на то время, пока устраняются последствия аварии.

Анализ рисков перед составлением плана аварийного восстановления
Планирование мер по аварийному восстановлению всегда начинается с анализа рисков для бизнеса (BIA – Business Impact Analysis). В рамках такого исследования оценивают состав основной IT-инфраструктуры и работающие сервисы. Вторым этапом является определение требований и учета возможных рисков для параллельной системы.
BIA расставляет приоритеты для критически важных компонентов и приложений. Делается это совместными усилиями IT-специалистов и продукт-менеджерами. Хранимым данным и работающим сервисам присваивают следующие классификации:
- Критическая важность – приоритет №1. Сюда относят все данные, которые не должны быть потеряны в случае аварии, а также оборудование и сервисы, работу которых необходимо восстановить максимально быстро. Все, что приносит компании основной доход, должно получить приоритет №1 на восстановление.
- Вторичная (semi-important) важность – приоритет №2. Приложения, оборудование и сервисы, простой которых, измеряемый в часах, критично не повлияет на работу компании и не скажется на ее доходах.
- Низкий уровень приоритета – приоритет №3. Компоненты и сервисы, которые никак прямо не влияют на доходы компании. Их многочасовой простой, прямо не скажется на доходах бизнеса.
Анализ должен содержать оценку того, как вероятная авария может повлиять на бизнес-процессы компании. Каждому приоритету должно быть присвоено допустимое время простоя, у каждого уровня должен быть собственный SLA. Это особенно важно, если инструменты или процессы аварийного восстановления бизнес собирается доверить внешним подрядчикам.
В описаниях услуг крупные европейские провайдеры заявляют возможное время простоя доступных для аренды серверов в процентах. Обычно оно составляет 99%. Чем выше число после запятой, тем качественнее и безопаснее сервис.
| Значения SLA | |
| Доступность сервисов | Максимальное время простоя в год |
| 99 % | 3,65 дней |
| 99,9 % | 8,76 часов |
| 99,95 % | 4,38 часов |
| 99,99 % | 52,56 минут |
| 99,999 % | 5,26 минут |
Когда приоритеты расставлены, оценивают возможные риски для работы основной и параллельной инфраструктур. К таковым обычно относят:
- Внешние угрозы. Любые опасности, возникающие вследствие внешних преднамеренных или случайных действий человека: кибератаки, вооруженные нападения, поджоги, кражи и т.д.
- Внутренние угрозы. Инциденты, связанные с преднамеренными или случайными действиями обслуживающего персонала и сотрудников компании, имеющих доступ к инфраструктуре. Сюда традиционно относят: непреднамеренные ошибки, утрату реквизитов для доступа, халатность, преднамеренный саботаж и т.д.
- Угрозы социального и техногенного характера. События, в основе которых лежит человеческий фактор: аварии на станциях снабжения, истощение ресурсов, военные и политические конфликты, эпидемии, и т.д.
- Природные катастрофы. Естественные процессы или погодные явления: штормы, наводнения, оползни, лесные пожары, землетрясения и т.д.
Может показаться, что такие экзотические угрозы, как вулканы или наводнения, крайне редко становятся причиной уничтожения хорошо защищенной IT-инфраструктуры, однако это случается намного чаще, чем принято считать. При этом аварийное восстановление системы (disaster recovery site) может осложняться погодными условиями и проблемами со снабжением.
В 2012 году ураган Сэнди обрушился на северо-восточное побережье Соединенных Штатов Америки. Штаб-квартира и важнейший информационный хаб крупной американской телекоммуникационной компании, располагавшийся в районе Нижнего Манхеттена в Нью-Йорке, был затоплен в результате ливней. Вода затопила три с половиной из пяти подземных этажей здания, были уничтожены резервные генераторы, повреждены распределительные системы и критически важные кабельные шахты. Технические работы по восстановлению несколько дней затруднялись из-за плохой погоды, отсутствия стабильного электроснабжения, заблокированных дорог и принудительной эвакуации.
Определение требований и подбор решений по аварийному восстановлению
После оценки угроз и рисков регламентируют технические требования по аварийному восстановлению. Для этого используют два основных параметра, определяющих стоимость создания и содержания параллельной инфраструктуры: RTO (Recovery Time Objective) и RPO (Recovery Point Objective). Условия по ним всегда исходят от руководителей компании. Следует заметить, что параметры RTO и RPO всегда определяют после утверждения SLA по основным сервисам внутри компании. Эти значения являются важной частью договора с внешними контрагентами и поставщиками услуг.
- RTO – параметр, определяющий максимальное время простоя системы в случае аварии. Он помогает определить, какой урон будет нанесен бизнесу, если ключевые сервисы или IT-инфраструктура окажутся недоступны в течении минут, часов или дней. Обычно выбирают самое высоконагруженное время суток и считают возможные потери за этот период. Если, например, максимально допустимое время простоя (RTO) равно 1 часу, значит, система должна восстановить работу не позднее, чем через 60 минут.
- RPO – параметр, определяющий частоту резервного копирования. Если RPO равен 24 часам, значит, резервную копию необходимо создавать с периодичностью 1 раз в сутки. Руководящему персоналу компании необходимо определить допустимое время простоя IT-инфраструктуры так, чтобы затраты на сохранность данных не превышали ущерба от потери информации.
Задача обслуживающего персонала – обеспечить утвержденные показатели с учетом бюджета и реального положения дел. Чем ниже значения RTO и RPO, тем дороже и сложнее в организации система аварийного восстановления. На практике процесс определения RPO и RTO выглядит примерно так:
- IT-персонал запрашивает у руководства допустимые параметры простоя и время на восстановление, получает ответ.
- В соответствии с показателями IT-специалисты составляют бюджет и отправляют его на согласование.
- Если требуется корректировка, параметры и бюджет совместными усилиями меняют до приемлемых значений.
Модели аварийного восстановления из облака
Создавать параллельную инфраструктуру можно двумя способами: организовать полную копию работающей системы собственными усилиями или использовать облачные технологии и сервисы (DRaaS). Первый способ является очень дорогим и подходит только крупным предприятиям и корпорациям. Второй способ более предпочтителен для больших и средних компаний с развитой IT-инфраструктурой, поскольку предполагает гибкие настройки хранения и восстановления информации.
Для аварийного восстановления из облака существует три модели, каждую из которых выбирают в зависимости от предъявляемых бизнесом требований.
- Резервное копирование и восстановление из бэкапа. Самая простая модель, которая реализуется по системе Active – Passive. Данные копируются из активной системы в облако в виде бэкапа. Параметры RTO и RPO в этом случае прямо зависят от объема данных, но, как правило, составляют не менее часа. Это самый бюджетный вариант, который хорошо подходит только в том случае, если время простоя, измеряемое в часах, не является для бизнеса критичным и допускается относительно небольшая потеря информации.
- Репликация по модели Active – Standby. В этом случае данные из активной системы передаются в облако, а подготовленные виртуальные машины находятся в режиме ожидания. RTO в этом случае редко превышает 30 минут, а RPO – 15 минут. Такая модель хорошо подходит для сервисов e-commerce и BigData.
- Репликация по модели Active – Active. В основе этой модели зеркальная репликация: данные синхронно передаются в дублирующую облачную систему, которая работает параллельно основной. RTO при такой модели редко превышает 30 секунд, а RPO равно нулю. Подобная модель является безальтернативной для банков, крупных IT-компаний и государственных учреждений.
Ведущие европейские провайдеры могут предложить готовые решения по аварийному восстановлению (disaster recovery services) из облака по любой из моделей. Комплексные системы репликации и восстановления обеспечивают высокую доступность средств восстановления (high availability disaster recovery) и реализуются на основе программных продуктов от ведущих мировых производителей: Microsoft, Veeam, Cohesity, Commvault, Dell Technologies, Rubrik и Veritas.
Разработка плана DRP (DRP Plan)
Когда ключевые требования бизнеса к системе известны, выбрано программное решение и обоснован бюджет, приходит время разработки плана на случай аварии. Создание формального документа начинается с инвентаризации оборудования, программного обеспечения, работающих сервисов и вовлеченных в обслуживание человеческих ресурсов.
При длительной эксплуатации системы могут накапливаться незадокументированные настройки, могут возникнуть проблемы с организацией уровней доступа и коммуникациями в рабочем коллективе, которые будут неочевидны до возникновения инцидента. Кроме готового документа в итоге подобная работа помогает более детально разобраться с положением вещей здесь и сейчас. Весь процесс разработки плана можно представить в несколько этапов.
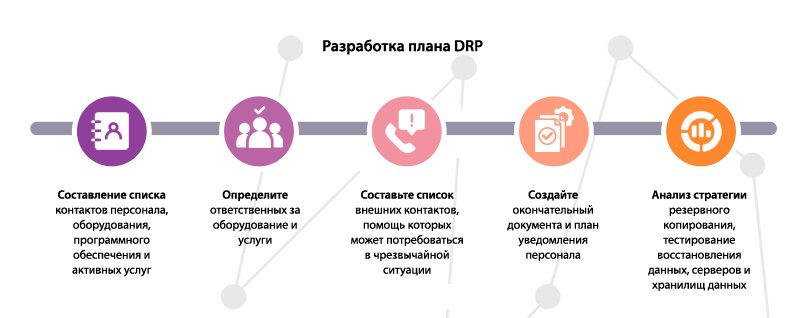
Составление списка контактов персонала
Актуализируйте список всех сотрудников, причастных к обслуживанию и контролю IT-инфраструктуры. У каждого запросите резервные контакты и каналы связи (близкие родственники, друзья). Информированность о том, где может находиться тот или иной сотрудник в момент инцидента значительно снижает время на устранение аварии.
Создание списка оборудования, ПО и активных сервисов
Составьте список всего задействованного в системе оборудования, программного обеспечения и рабочих сервисов. Затем создайте схемы внутреннего и внешнего взаимодействия всех элементов, оцените загруженность электронных коммуникаций.
Определение ответственных за работу оборудования и сервисов
Проверьте или определите роли и уровни ответственности для каждого вовлеченного сотрудника:
- Назначьте заместителей на случай отсутствия руководства.
- Проверьте, отвечают ли профессиональные навыки ответственных специалистов требуемому уровню обслуживания. Если есть сомнения, проведите дополнительное обучение.
- Проверьте уровни доступа и актуальность логинов и паролей для аварийного доступа.
- Создайте документ с зафиксированным распределением ролей и уровней ответственности. Дополнительно в схему можно продублировать списки контактов ключевых сотрудников, чтобы сократить время на поиски в момент инцидента.
Создание списка внешних контактов
Составьте список контактов для связи с контрагентами и партнерами, чья помощь может понадобиться в случае аварии. В документе должны быть указаны каналы для связи с экстренными службами, поставщиками услуг, оборудования и программного обеспечения, техподдержкой внешних сервисов. Отдельно пропишите контакты для оперативной связи с коммунальными службами.Это необходимо на случай серьезных инфраструктурных аварий.
Подготовка финального документа и оповещение персонала
Задокументируйте порядок и характер действий в случае аварии. Создайте несколько копий в электронном и бумажном виде. Одну из бумажных копий храните в надежном месте, например, в сейфе. Сделайте рассылку с планом DRP для всех сотрудников, чье участие предполагается при устранении последствий инцидента.
Анализ стратегии резервного копирования
Проверьте, соответствуют ли действующие схемы резервного копирования необходимому уровню безопасности. После составления и утверждения плана проведите тестовое восстановление данных, серверов и хранилищ информации. Настройте оповещение при сбоях резервного копирования.
Практика показывает, что система уведомления о сбоях резервного копирования неэффективно работает в том случае, если сообщение о проблеме отправляется на электронную почту. Почтовые ящики ответственных специалистов часто перегружены системными сообщениями с различных сервисов и важное предупреждение можно просто упустить из вида. Мы всегда рекомендуем настраивать систему предупреждения так, чтобы в случае повторяющегося сбоя система отправляла SMS на номера телефонов менеджмента компании и главы IT-службы.
Тестирование и техническое обслуживание IT-инфраструктуры
К сожалению, подготовить DRP и провести единичный тест параллельной инфраструктуры никогда не бывает достаточно. Система постоянно меняется: устанавливаются обновления ПО, добавляется новое оборудование, появляются новые сервисы. Ответственная группа IT-специалистов должна регулярно проводить учения и поддерживать резервные мощности в рабочем состоянии.
Для этого обычно составляют график тестирования, куда закладывают различные сценарии возможных инцидентов: падение сервера, кибератака, отключение электроснабжения, утрата доступов и т.д. Команда администрирования должна быть готова к любому повороту событий.
В идеале необходимо создать систему восстановления с работающим аварийным переключением (failover). Чтобы параллельная инфраструктура запускалась автоматически и максимально быстро, создают механизм, при котором основная система постоянно обменивается с дублирующей особым периодическим сигналом – «пульсом» (“hardbeat”). Как только резервная сеть перестает получать пульс, то запускается сама. Канал, по которому передаётся «пульс» тоже должен быть продублирован.
Возможных вариантов организации DR очень много. Если вам нужна помощь в создании отказоустойчивой системы проконсультируйтесь со специалистами по информационной безопасности. У всех крупных европейских провайдеров есть готовые решения по аварийному восстановлению из облака. Получить консультацию на этот счет всегда можно бесплатно.
или закажите бесплатную консультацию
Как составить план аварийного восстановления ИТ-инфраструктуры. Пошаговая инструкция от провайдера.
Подробный план аварийного восстановления для бизнеса
Специально для вас мы изучили расценки на услуги Disaster Recovery от 20 крупных европейских провайдеров. Если вы хотите получить эту информацию, оценить или скорректировать собственный DRP план, забронируйте бесплатную консультацию со специалистом по облачным сервисам. Мы поможем посчитать смету, затраты на реализацию, расскажем про лизинг оборудования для аварийного восстановления. Забронировать разговор можно здесь.
Автор статьи Ольга Буянова Консультант по серверному оборудованию и организации центров обработки данных