Contents
- 1 Brief information about the customer and the start of our cooperation
- 2 What is better: relocating to a new data center or building a highly resilient IT infrastructure?
- 3 Project on infrastructure distribution among 3 data centers to increase resilience
- 4 How the highly resilient IT infrastructure project was implemented
- 5 Challenges we faced during the project
- 6 Results and benefits for the customer
- 7 Continued cooperation after the implementation of a highly resilient IT infrastructure project
- 8 In short
When working with an oil and gas company (the customer), we had to solve many different tasks, including server configuration, moving to a new data center, working on their IT infrastructure resilience and creating DDoS protection. This is the story of the largest project with our partners, a one-of-a-kind IT system design, the challenges we faced, the reasons for choosing this solution and the results.
Brief information about the customer and the start of our cooperation
The main customer’s focus is the oil and gas industry. The business started with a few petrol stations. After more than 20 years on the market, this small company has grown into a large holding company with a network of petrol stations and complexes across Europe, including restaurants, cafes, shops and fuel quality control laboratories. It actively participates in charitable and social projects (initiatives), cares for the environment, invests in building ecosystems and cares for people with disabilities.
Initially, the customer’s IT infrastructure was located in one of the data centers (DC) in Frankfurt am Main. The data center had 2 racks with EMC (Dell), Cisco and HP servers (they later completely switched to HP). When the company was small, these resources were sufficient to keep it running smoothly. However, they required maintenance. With the head office and all other departments, including IT, located in a different country, the customer needed a trusted provider to efficiently and quickly resolve ongoing issues in the Frankfurt data center. This is exactly what our company was able to do.
Our work started with small tasks. We were hired as remote hands to perform various tasks related to the functionality of the hardware and networks in the data center where the customer’s IT infrastructure was placed: connecting, switching, creating a new connection, performing some other one-off tasks. At first, the company’s engineers came to get to know us and see our technical team in action.
It worked out all right, we gained the customer’s trust and they began to call on us more and more often with more and more demanding tasks. After several years of working together, they had to move racks within the data center and immediately called us to do it.
Moving within the data center: the process and the team
The EMC rack server was large and non-standard, which meant a lot of work:
- moving the cabinets to a new place;
- dismantling, packing, moving and transporting the old equipment to the company’s office (we hired a transportation company to do this);
- helping with the installation of new equipment and changing network connections.
We usually have 2 people working on standard applications, which is enough for typical tasks. Rack space is limited and there is no point in employing more people as they would just get in each other’s way. However, in huge tasks such as moving to a data center, where servers need to be connected or hardware needs to be removed, at least 3 people are involved.
What is better: relocating to a new data center or building a highly resilient IT infrastructure?
Although the overall system worked reliably, all of their equipment located in one data center was still a point of vulnerability. If there was a failure due to an accident or natural disaster, the data center would be affected causing downtime to the entire system and significant losses with reputational damage.
The company was growing rapidly, new operational directions were emerging and limited IT resources were becoming a pressing issue. Petrol stations operate around the clock, payments and other transactions take place 24/7. According to the holding’s business concept, all their employees should have constant access to the company’s information resources from any place in the world. As a result, security is critical to the business — with any disruption to the IT infrastructure having a direct impact on the company’s image and revenue.
In addition, a few years ago they decided to fully digitalise their business processes. This required a robust, fault-tolerant system protected from accidents and cyber attacks. The IT department and the security department had one goal: to maximise the resilience of the infrastructure and to move to another data center if necessary.
Why build a distributed infrastructure?
Even the most reliable DCs with 99.99% SLA have unforeseen situations related to loss of communications, power outages, etc. At the same time, even a short outage causes a long downtime for customer structures, as they need time to fully recover: reload, check their databases, start up. As a result, 10 minutes of downtime reported by a data center mean 3-4 hours for a customer. Sometimes it takes half a day or even a full day to get back to work, if a specialist has to be called in to check a particular piece of equipment.
To increase their resilience, stable companies with resources typically spread their IT infrastructure across multiple data centers in different locations.

A distributed structure minimises risks in the first place. For example, if you experience power issues in one DC, you can switch to another DC and continue to run as usual. Or you can deploy services and data from a separately stored backup in your third DC if necessary. It is almost impossible to affect the stability of a system that is physically distributed across multiple data centers.
Some companies choose to move to another data center if they face availability failures, but distribution is a much more effective way to solve this problem. It is for a reason that well-known cloud providers and large international corporations with higher IT infrastructure resilience requirements use distribution strategies. Our customer decided to choose this strategy too.
Project on infrastructure distribution among 3 data centers to increase resilience
It was decided to use the triangle principle with three data centers (one main DC and two additional DCs). The data centers should be interconnected by physical optical lines.
The IT infrastructure project was designed by the company’s specialists. We were asked to help with colocation in two additional DCs we work with.
When the preliminary implementation option was ready, the technical experts in charge of the project came to Frankfurt in person to discuss the details. We were also asked to advise on the interconnection of the data centers, the selection of redundant lines and a number of other issues.
We also provided an equipment calculation based on the customer’s list. However, due to internal constraints, it turned out to be more profitable for the company to purchase the equipment in their home country and then ship it to our data center in Frankfurt. This meant fewer expenses on equipment but more complicated transportation: we had to build a complex logistics chain and choose reliable carriers for the valuable equipment.
Why it was decided to build a distributed IT structure in Frankfurt
According to the customer, simply moving to another data center to improve the resilience of the IT infrastructure made no sense. However, distributing resources across three data centers in Frankfurt was beneficial in terms of reliability and service quality for a number of reasons:
- Frankfurt am Main is one of the largest cities in Europe in terms of data centers and is the central telecommunications hub where almost all operators and Internet service providers are concentrated because of the greatest network resilience;
- the entire IT infrastructure is maintained within one location.
How the highly resilient IT infrastructure project was implemented
Migration, distribution of resources to different data centers: organisational considerations
It is our standard to meet with customers face-to-face or online before starting a project. We use messengers like Telegram, WhatsApp or Skype. We also create a group and add everyone involved in the project to it. If any questions arise, we resolve them interactively.
In this case, we followed this rule: first we discussed the project in general during conference calls and clarified the details, wants and needs. Then we asked for technical documentation. The customer’s engineers prepared and provided a network design diagram, communication table, equipment placement and connection schemes. After checking the customer’s documents, our specialists made an implementation plan and planned operations for each stage. The next step was to agree on a date and time for the works to be carried out.
We informed the customer of the completion of each stage in the chat so that they could check the connection, see if the nodes were available, etc. After getting their approval, we moved on to the next stage. If the company’s engineers needed additional time for testing or rework, they would let us know in the same chat.
The work we did as part of building the distributed infrastructure
The customer’s engineers prepared and provided installation/connection diagrams for the necessary equipment in two data centers we cooperate with. We were also asked to arrange connections between the first data center to the new two centers. Our engineers did all the work to place and connect the equipment, from unpacking to startup.
In short, it was an end-to-end project with three major areas of work: logistics, commissioning and administration.
Our tasks:
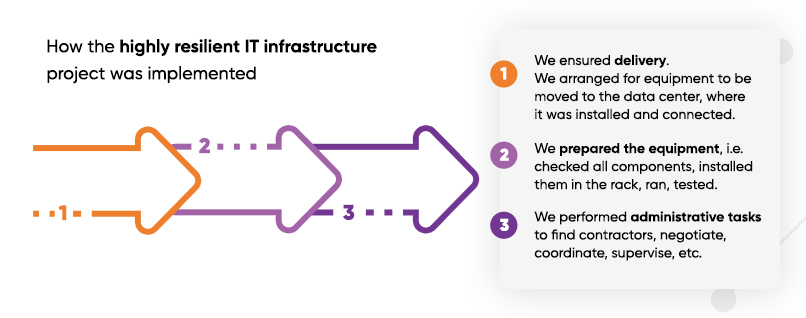
- We ensured delivery. The equipment was delivered to us, then we arranged for it to be moved to the data center, where it was installed and connected. We collected it from the carrier, transported it to the installation site, unpacked it and repacked it if necessary.
- We prepared the equipment, i.e. checked all components, installed them in the rack, plugged in, connected, configured, ran, tested. We also had to synchronise all three DCs with each other using optical lines and ensure remote control when done.
- We performed administrative tasks to find contractors, negotiate, approve activities, coordinate, supervise, etc.
We assigned our coordinator and three of our engineers to join the implementation of the project. The customer had four people involved (one person from each IT department and the technical director).
It should be added that our company works with HP, Dell, Cisco, Juniper and Huawei, and the customer regularly orders maintenance services for their equipment through us. In this case, we also brought in a vendor specialist.
Challenges we faced during the project
We already had experience in moving and distributing customer IT infrastructure across different data centers (see the gambling case). So the customer’s task was not technically difficult. However, the project had some features that had to be taken into account during the implementation. The main feature was to focus on three DCs in Frankfurt. This is a unique case because usually customers choose one or two data centers in different locations not far from each other.
There were some minor difficulties in getting the lines up and running. When a line is allocated, the data center informs its client that it is ready to be connected to the rack with a cable through a port provided. By allocating the line, the DC thinks it is ready to be used by default. However, some lines are faulty. There are many options where the fault can be found: in the meet-me room, at the physical connections of the optical cables, on the way to the cage or at the point of connection to the rack server.
According to data center regulations, technicians are supposed to check and restore the line. This can be challenging because of the human factor: when a connection at some point is loose or there is an overlooked disconnection somewhere, etc. The result is a big blackout, no power and no connection. Such situations are quite common after moving to another data center, and many newly moved companies simply do not know what to do in such cases. They often buy another line to avoid dealing with the service provider while hoping that the second one will be done right.
In this project, we also faced this problem: the line was off after the check. It is very inconvenient and difficult for the customer to deal with such problems. Firstly, because they are far away. Secondly, because of the language barrier: the issue has to be described in detail in a foreign language. We had to contact the local engineers and coordinate two data centers to avoid this. We created tickets for both of them at the same time and looked for the fault. When we found it and fixed it, we double-checked everything. In the end, the problem was solved and the line connected all the data centers.
The main difficulty companies encounter when moving to and connecting DCs is the initial set-up phase. There are cases when we assemble the rack according to the diagram provided by our customer, we connect and configure everything right, but something doesn’t go as planned when the customer launches the system. In these cases, we provide console access from our equipment and monitor the signals from both sides. The customer technicians can configure the equipment from their desks using console access.
Results and benefits for the customer
As a result of our work, the customer got their IT infrastructure distributed across three data centers and resilient enough for their operations. Two new data centers have been connected to the company’s original data center:
- our DC (used as one of the main hubs);
- a backup DC (primarily for backups).
All three DCs are located in Frankfurt.
The customer was very satisfied with the results of partial moving to additional data centers and the opportunity to save money. The fact is that building an IT infrastructure (especially to improve resilience) is a time-consuming and labour-intensive process. It is not possible to do everything in a day or two, and here is why.
- Equipment has to arrive at the data center, it needs to be unpacked and installed by a certain time since it can’t be stored in the DC for long. Then everything has to be connected, plugged in and configured. These operations alone can take more than two or three weeks.
- It is necessary to communicate with all the parties involved and coordinate the phases of the work as they are to be carried out at different times. It is important to find reliable service providers and agree on work steps with them. We communicate with the DC to ensure that communication channels are connected and there is power in the rack. If a vendor technician is required, we make an appointment and meet them when they arrive in the DC.
In addition to the technical tasks we do, it is vital to communicate and coordinate the parties involved to ensure that moving to new data centers and creating a distributed IT structure is completed on time and to a high standard. If a company based in another country wanted to set up an IT infrastructure in three data centers, it would have to send an entire team of 3-4 specialists on a business trip for at least a month. Don’t forget accommodation, meals, travel and other associated costs. We carried out all the work remotely and helped the customer to save time as well as money.
An important aspect of the project was the timing of the implementation of the IT infrastructure. Our technicians effectively planned the implementation stages and completed all the work within a month.
Continued cooperation after the implementation of a highly resilient IT infrastructure project
Since we established a trusting partnership, the customer has entrusted us not only with the maintenance of the IT infrastructure after moving to our data center but also with other responsible tasks. In particular, we undertook connection works when the server equipment was changed to HP. According to the contract with the manufacturer, the initial setup and initialisation of the system had to be carried out by the manufacturer’s representative, as the process of activating the data storage system is a complex challenge. We communicated with the manufacturer, invited a specialist, participated in the preparation and handed over the already installed and fully operational equipment to the company’s engineers.
Remote works
After the implementation of the IT infrastructure resilience project, the customer entrusted our company with virtually all matters relating to remote works at all sites in Frankfurt: technical, logistical and organisational.
We are the company’s point of contact and we also take care of regular server, module, network acceptance and setup as well as system upgrades. We are also responsible for dismantling the old hardware and transporting it to the company’s offices.
All new equipment units, including one-of-a-kind and expensive ones, are sent to our data center for a check. We unpack it, check it according to the list of components, take pictures and send this information to the customer’s IT department. Then we get the distribution, cabling and replacement plans and carry out the upgrades. This has to be done on a regular basis because the infrastructure is regularly upgraded: they started with gigabit options, then switched to 10GB with the latest upgrade to 25GB.
DDoS solution
In 2018, two years after setting up the distributed infrastructure, the customer’s security department assigned a new challenging task to us. DDoS solutions had to be implemented for certain services, i.e. they needed to create a channel protected against cyber attacks.
At this time, we were switching to new DDoS protection methods at our company and were working on L3 network protection. It was a good and smart solution. It fitted the customer’s technical means, so we offered to run and test it. The company even had a pre-ordered attack on their sites to test and check the nodes, and the DDoS protection worked perfectly.
In short
Obviously, the company with a network of petrol stations across Europe and many other activities is very sensitive to any disruption to its information structure. It is vital for a diversified business to have uninterrupted availability 24/7. If communication is lost even for a minute, financial and reputational damages can be enormous. For example, a client fills up their car at a petrol station or orders a meal at a restaurant and can’t pay for it because the payment terminal has no internet connection at the moment. Cases like these are critical to business. This is why it is so important to build an IT infrastructure with a high level of resilience and protection against cyber attacks. This was the task set by the customer and met in full by the hands and efforts of our technical staff.
What began as a typical remote working cooperation has gradually developed into a strong and trusted partnership. We helped them implement a large project and selected a reliable DDoS solution. They now have two racks with us instead of one, we provide them with maintenance services through our partners at Cisco and Huawei and we are the company’s point of contact in Frankfurt.
Case study: relocating to a new data center in Frankfurt and building a distributed infrastructure
Write us a message to get additional information.
or book a free consultation
If you need advice on moving to a data center in Frankfurt, DDoS protection or your company needs a distributed IT infrastructure, please contact us. We can help you find the best solution for your business needs and project budget.
Article author
Olga Boujanova
Consultant on server hardware and data center organization
