Contents
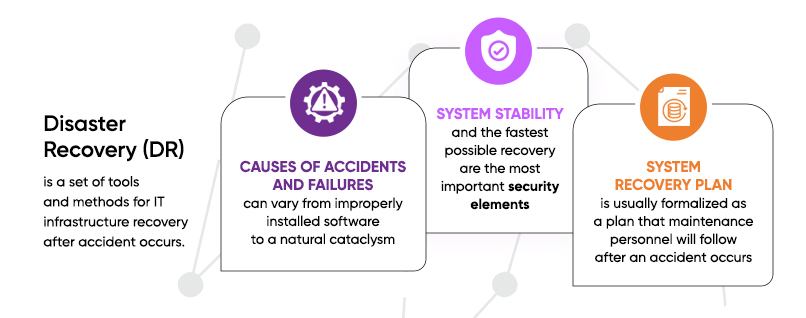
Disaster Recovery (DR) is a set of tools and methods for IT infrastructure recovery after accident occurs. Causes of accidents and failures can vary from improperly installed software to a serious natural or man-made cataclysm. System stability and the fastest possible recovery from critical damage are the most important security elements of almost any modern business that uses information technologies.
A system recovery plan is usually formalized as a plan that maintenance personnel will follow after an accident occurs. Disaster Recovery Plan (DRP) is primarily required for organizations with developed IT infrastructure. Smaller businesses sometimes only need to properly implement a backup scheme to ensure an acceptable level of security.
How a disaster recovery plan can safeguard the website and preserve critical company data
The main objective of disaster recovery measures is to avoid negative consequences for services or minimize damage in the event of an accident. A full planning (Disaster Recovery Planning) has several objectives:
- Establish alternative and redundant operating systems in advance.
- Train and prepare personnel for possible accidents.
- Minimize damage and prevent possible destruction of the IT infrastructure.
- Limit system failure time to acceptable values or eliminate service interruption altogether.
- Minimize the economic impact in the event of an accident.
- Ensure rapid service restoration.
The number of tools used and measures taken is directly related to the scale of the IT infrastructure.
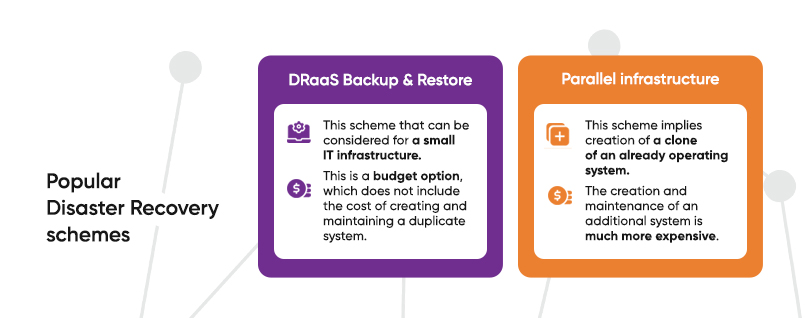
Popular Disaster Recovery schemes
The list of disaster recovery measures is determined based on the probable risks and feasibility of spending on the required level of security. For example, a small company operating a single server and a limited set of network hardware probably does not need to develop and implement full-fledged DRP planning (drp planning). In this case, regular cloud backups and cloud-based recovery tools will suffice. But actively growing businesses and large enterprises require comprehensive disaster recovery solutions.
- DRaaS Backup & Restore is a scheme that can be considered in the context of Disaster Recovery measures for a small IT infrastructure. This is a budget option, which does not include the cost of creating and maintaining a duplicate system. You only have to pay for the volume in the cloud and the uptime of virtual machines at the time of the accident. Almost all major European providers can provide off-the-shelf cloud backup and recovery solutions.
- Parallel infrastructure implies creation of a clone of an already operating system. In case of an accident in the main structure, the parallel one is automatically activated. This method allows to significantly reduce costs: the startup time of the duplicate infrastructure can be from several tens of minutes to a day. At the same time, the creation and maintenance of an additional system is much more expensive, so it is used by companies for which downtime of tens of minutes is critical.
In this article, let’s take a closer look at the peculiarities of parallel infrastructure deployment, since it is for this scheme that a disaster recovery plan (DRP) can be an important security element.
When creating a parallel infrastructure, it is not necessary to create a complete clone of the main system. Often, less productive hardware is reserved for disaster recovery. Moreover, only data and services that are critical to business are transferred to the backup servers: DRP, MES, CRM, etc. For example, if the main IT infrastructure is represented by ten servers, the parallel IT infrastructure can be run on two backup servers, their task is to provide an acceptable level of access to the most important data and services only while the consequences of the disaster are being eliminated
![]()
![]()
DRP Plan: The Blueprint for IT Infrastructure Resilience
Disaster recovery planning always starts with analyzing the risks to the business (BIA – Business Impact Analysis). As part of this study, the composition of the main IT infrastructure and running services are assessed. The second step is to determine the requirements and consider possible risks for the parallel system.
BIA prioritizes critical components and applications. This is done jointly by IT specialists and product managers. Stored data and running services are assigned the following classifications:
- Critical importance – priority #1. This includes all data that should not be lost in the event of an accident, as well as hardware and services that need to be restored as quickly as possible. Anything that generates major revenue for the company should be prioritized #1 for recovery.
- Secondary (semi-important) importance – priority #2. Applications, hardware and services which downtime, measured in hours, will not critically affect the company’s operations or revenues.
- Low priority level – priority #3. Components and services that have no direct impact on the company’s revenue. Their many hours of downtime will not directly affect business revenues.
The analysis should include an assessment of how a possible accident could affect the company’s business processes. Each priority should be assigned an allowable downtime, and each level should have its own SLA. This is especially important if the business is going to outsource disaster recovery tools or processes.
In their service descriptions, major European providers state the possible downtime of available servers for rent as a percentage. Usually it is 99%. The higher the number after the decimal point, the better and safer the service is.
| SLA values | |
| Availability of services | Maximum downtime per year |
| 99 % | 3.65 days |
| 99.9 % | 8.76 hours |
| 99.95 % | 4.38 hours |
| 99.99 % | 52.56 minutes |
| 99.999 % | 5.26 minutes |
When the priorities are set, the possible risks to the operation of the core and parallel infrastructures are assessed. These usually include:
- External threats. Any hazards resulting from external intentional or accidental human actions: cyber-attacks, armed attacks, arson, theft, etc.
- Internal threats. Accidents, related to the intentional or accidental actions of maintenance personnel and company employees, who have access to the infrastructure. This traditionally includes: unintentional errors, loss of access credentials, negligence, intentional sabotage, etc.
- Social and technological threats. Events based on human factors: accidents at supply stations, resource depletion, military and political conflicts, epidemics, etc.
- Natural disasters. Natural processes or weather events: storms, floods, landslides, forest fires, earthquakes, etc.
Exotic threats such as volcanoes or floods may seem like a rare occurrence when a well-protected IT infrastructure is destroyed, but it happens far more often than is commonly believed. However, disaster recovery of the system (disaster recovery site) can become more complicated due to weather and supply issues.
In 2012, Hurricane Sandy struck the north-east coast of the United States of America. The headquarters and critical information hub of a major American telecommunications company, located in the Lower Manhattan neighborhood of New York City, was flooded as a result of heavy rains. Water flooded three and a half of the building's five underground floors, destroyed backup generators, damaged distribution systems and critical cable shafts. Technical recovery efforts were hampered for several days by bad weather, lack of stable power, blocked roads and forced evacuations
![]()
![]()
Defining requirements and selecting disaster recovery solutions
After assessing the threats and risks, technical requirements for disaster recovery are defined. For this purpose, two main parameters that determine the cost of creating and maintaining a parallel infrastructure are used: RTO (Recovery Time Objective) and RPO (Recovery Point Objective). The conditions on them always come from the company’s managers. It should be noted that RTO and RPO parameters are always defined after the SLA for the main services is approved inside the company. These values are an important part of the contract with external contractors and service providers.
- RTO: parameter that determines maximum amount of downtime a system can experience in the event of an accident. It helps to determine how much damage will be done to the business if key services or IT infrastructure is unavailable for minutes, hours or days. It is common to select the most heavily loaded time of day and calculate the possible losses for that period. If, for example, the maximum allowable downtime (RTO) is 1 hour, the system must be restored to operation within 60 minutes at the latest.
- RPO: parameter defining the backup frequency. If RPO equals 24 hours, it means that a backup copy should be created once a day. The company’s management personnel need to determine the allowable downtime of the IT infrastructure so that the cost of data preservation does not exceed the damage caused by information loss.
The task of maintenance staff is to ensure that the approved values are met, taking into account budget and reality. The lower the RTO and RPO values, the more expensive and complex the disaster recovery system to organize. In practice, the process of determining RPO and RTO looks something like this:
- IT staff asks management for acceptable downtime parameters and recovery time and receives a response.
- In accordance with the parameters, IT specialists make a budget and send it for approval.
- If adjustments are required, the parameters and budget are jointly changed to acceptable values.
Cloud disaster recovery models
There are two ways to create a parallel infrastructure: to organize a full copy of the running system in-house or to use cloud technologies and services (DRaaS). The first method is very expensive and is suitable only for large enterprises and corporations. The second method is more preferable for large and medium-sized companies with developed IT infrastructure, as it implies flexible settings for information storage and recovery.
For cloud disaster recovery, there are three models, each of which is selected depending on the business requirements.
- Backup and restore from backup. The simplest model, which is implemented using the Active – Passive system. Data is copied from the active system to the cloud as a backup. In this case, RTO and RPO directly depend on the volume of data, but, as a rule, they are equal to no less than one hour. This is the most budget-friendly option, perfectly suitable only if downtime, measured in hours, is not business-critical and relatively little information loss is allowed.
- Active – Standby replication model. In this case, data from the active system is transferred to the cloud and the provisioned virtual machines are in standby mode. In this case, RTO rarely exceeds 30 minutes, and RPO rarely exceeds 15 minutes. This model is well suited for e-commerce and BigData services.
- Active – Active replication model. This model is based on mirror replication: data is synchronously transferred to a duplicate cloud system that runs in parallel with the main one. RTO in this model rarely exceeds 30 seconds, and RPO is zero. This model is the only alternative for banks, large IT companies and government agencies.
Leading European providers can offer off-the-shelf solutions for cloud disaster recovery services based on any of the above models. Comprehensive replication and recovery systems provide high availability disaster recovery and implemented on the basis of software products from the world’s leading vendors: Microsoft, Veeam, Cohesity, Commvault, Dell Technologies, Rubrik and Veritas.
Crafting a comprehensive DRP plan: expert recommendation
Once the key business requirements for the system are known, the software solution is selected and the budget is justified, it is time to develop a disaster recovery plan. Creation of formal document starts with inventory of hardware, software, running services and human resources involved in maintenance.
During long-term operation of the system, undocumented settings may accumulate, there may be issues with the organization of access levels and communications in the work team, which will not be obvious before the incident occurs. In addition to the completed document in the end, such work helps to understand the state of affairs in more detail in the here and now. The entire process of developing a plan can be visualized in several steps.
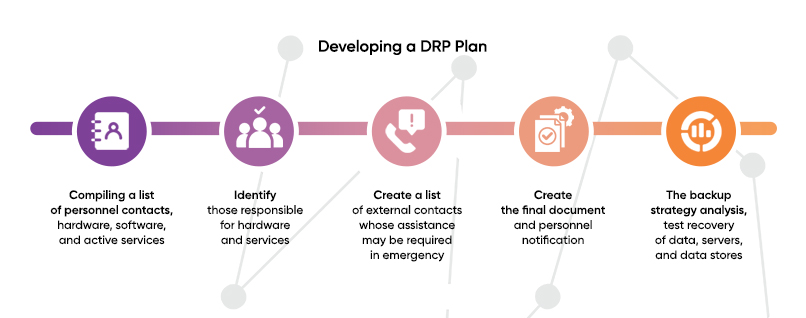
Compiling a list of personnel contacts
Update the list of all employees involved in the maintenance and control of the IT infrastructure. Ask everyone for backup contacts and communication channels (close relatives, friends). Knowing where a particular employee may be at the time of an incident significantly reduces the time it takes to fix an emergency. The knowledge of employee whereabouts at the time of the incident significantly reduces time spent on resolving the accident.
Create a list of hardware, software, and active services
Make a list of all the hardware, software, and operational services involved in the system. Then create internal and external interaction diagrams of all elements, assess the workload of electronic communications.
Identify those responsible for hardware and services
Review or define roles and levels of responsibility for each employee involved:
- Appoint deputies in case heads of departments will be missing during the accident.
- Check whether the skills of those responsible meet the required level of service. If in doubt, provide additional training.
- Check that access levels and emergency access logins and passwords are up to date.
- Create a document with a fixed assignment of roles and levels of responsibility. Additionally, contact lists of key personnel can be duplicated in the chart to reduce the time needed to find them during an incident.
Create a list of external contacts
Compile a list of contacts for communication with contractors and partners whose assistance may be required in the event of an emergency. The document should include channels for communication with emergency services, service providers, hardware and software suppliers, and technical support of external services. Separately specify contacts for prompt communication with utility services, in case of serious infrastructure failures.
Creating the final document and personnel notification
Document the order and nature of actions in case of an emergency. Create multiple copies in electronic and paper form. Keep one of the paper copies in a safe place, such as a safe deposit box. Distribute the DRP plan to all employees who are expected to be involved in the incident response.
The backup strategy analysis
Verify that your current backup schemes meet the required level of security. Once a plan is established and approved, test recovery of data, servers, and data stores. Set up alerts when backup failures occur.
Experience shows that the backup failure notification system does not work effectively if the problem is reported by email. The mailboxes of responsible specialists are often overloaded with system messages from various services and an important warning can be simply overlooked. We always recommend setting up the alert system so that in case of a recurring failure the system sends an SMS to the phone numbers of the company management and the head of the IT department.
![]()
![]()
Testing and maintenance of IT infrastructure
Unfortunately, it is never enough to prepare a DRP and perform a single test of a parallel infrastructure. The system is constantly changing: software updates are installed, new hardware is added, and new services are introduced. A responsible group of IT specialists should regularly conduct drills and keep backup capacities up to date.
For this purpose, a testing schedule is usually drawn up, where various scenarios of possible incidents are included: server crash, cyber-attack, power outage, loss of access, etc. The administration team must be prepared for any turn of events.
Ideally, a recovery system with a working failover should be in place. To make the parallel infrastructure start automatically and as fast as possible, a mechanism is created whereby the primary system constantly exchanges a special periodic signal – “heartbeat” – with the backup system. As soon as the backup network stops receiving the pulse, it starts itself. The channel on which the “heartbeat” is transmitted must also be duplicated.
There are so many possible ways to organize DR. If you need help in creating a fault-tolerant system, consult information security specialists. All major European providers have off-the-shelf solutions for cloud disaster recovery. You can always get advice on this free of charge.
Especially for you we have studied Disaster Recovery rates from 20 major European providers.
Disaster recovery plan: ensuring protection and fault tolerance for IT Infrastructure
Write us a message to get additional information.
or book a free consultation
If you want to get this information, evaluate or adjust your own DRP plan, book a free consultation with a cloud specialist. We can help you calculate estimates and implementation costs, and talk about leasing disaster recovery hardware. You can book a conversation here.
Article author Olga Boujanova Consultant on server hardware and data center organization